みなさん、こんにちは。
アステリアのキクチです。
前回はASTERIA Warpで条件分岐を行うコンポーネント、「BranchStartコンポーネント」「RecordFilterコンポーネント」をご紹介しました。
目次
どのコンポーネントもGUIで分岐を設定出来て、とっても便利なのですが、たくさんあると迷ってしまう!という方のために、この2つのコンポーネントとついでに条件付きレイヤーも加えて、フローのシンプルさやパフォーマンスを比較し、要件によってどのコンポーネントを使うのが最適なのか考えてみたいと思います。
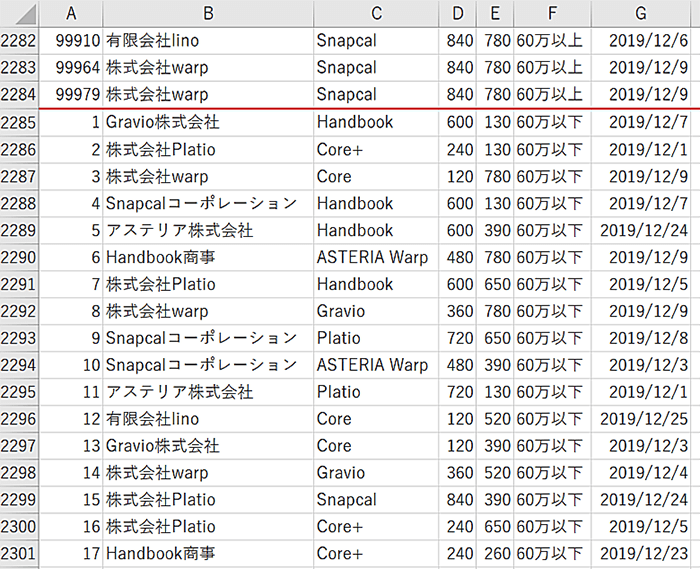
こんなCSVを用意しました。
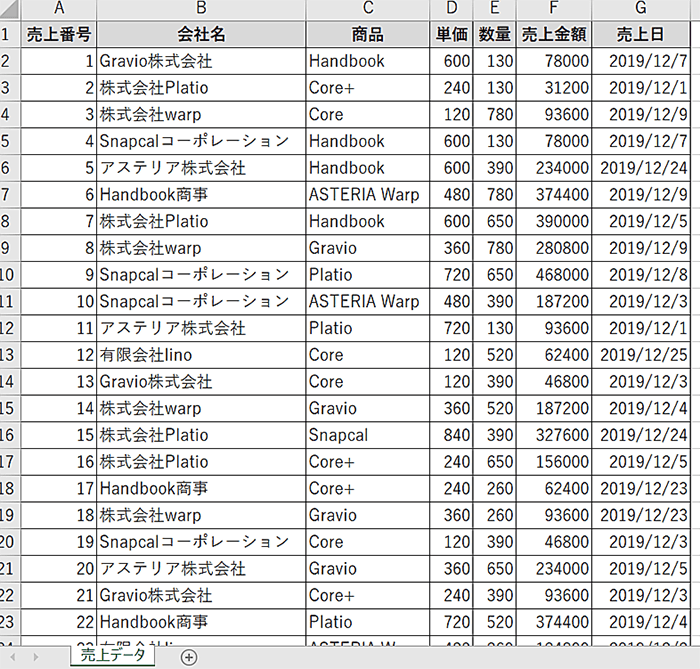
このデータの内、
という要件を満たすフローを各コンポーネントごとに作成してみます。
ついでに、上記↑のデータは10万件用意したので、パフォーマンスも比較してみましょう!
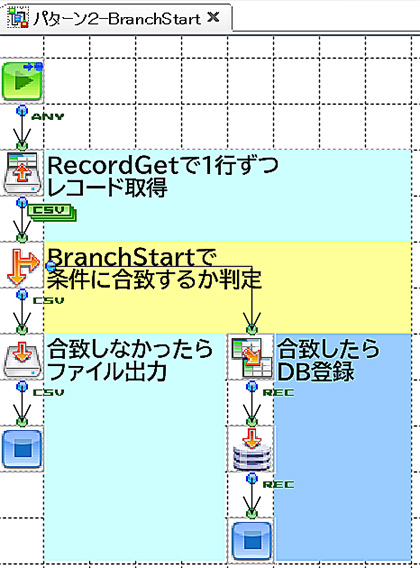
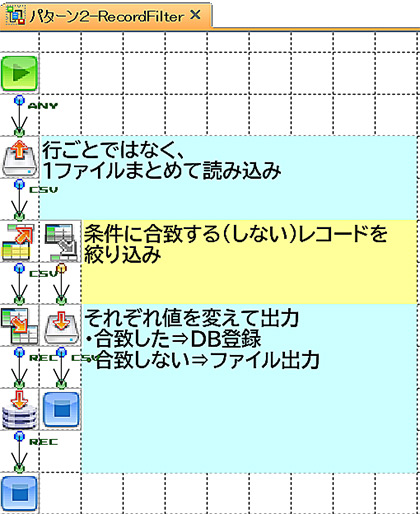
それぞれのフローはこんな感じになりました。
左から「BranchStart」「RecordFilter」「条件付きレイヤー」です。
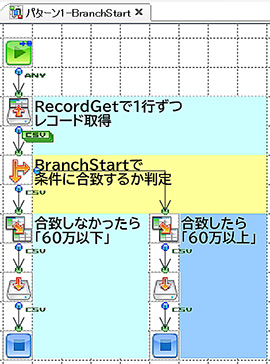
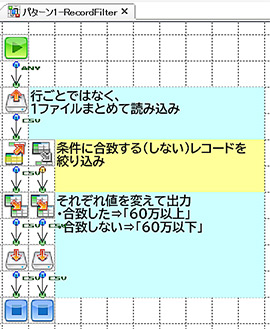
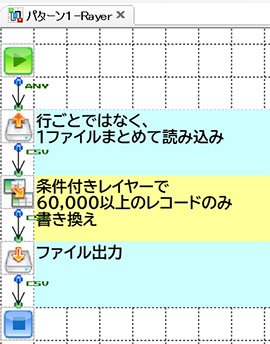
フローのシンプルさでいくと、ダントツで「条件付きレイヤー」ですね。
次いで「RecordFilterコンポーネント」、「BranchStartコンポーネント」でしょうか。
そして、お気付きでしょうか。
RecordFilterコンポーネントは、「条件に合致するレコードを絞り込む」だけではなく、「合致しなかったレコード」を出力するプロパティもあるんです。
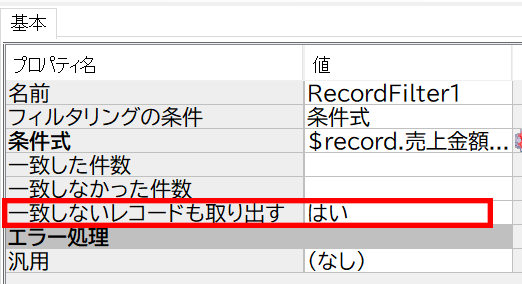
なので、レコードのフィルタリングだけではなく、今回のように“条件分岐“のように使うことも出来ますね!
さて、では実行してみましょう。
パフォーマンス結果は以下のようになりました。
| 単位:ミリ秒 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 平均 |
| BranchStart | 12507 | 12230 | 12733 | 12469 | 12518 | 12491.4 |
|---|---|---|---|---|---|---|
| RecordFilter | 507 | 514 | 371 | 501 | 272 | 433 |
| 条件付きレイヤー | 300 | 255 | 208 | 224 | 624 | 322.2 |
ふむふむ。大きな差が出ましたね。
BranchStartコンポーネントは1行ずつ条件に合致するか判定する=判定処理が10万回繰り返されるのでフィルタリング処理には向きません。
RecordFilterコンポーネントは速いです!
が、出力される結果(順序)には注意が必要です。
RecordFilterコンポーネントは動作の順序が
になります。
なので、それぞれの出力結果を1つのファイルにまとめると・・・
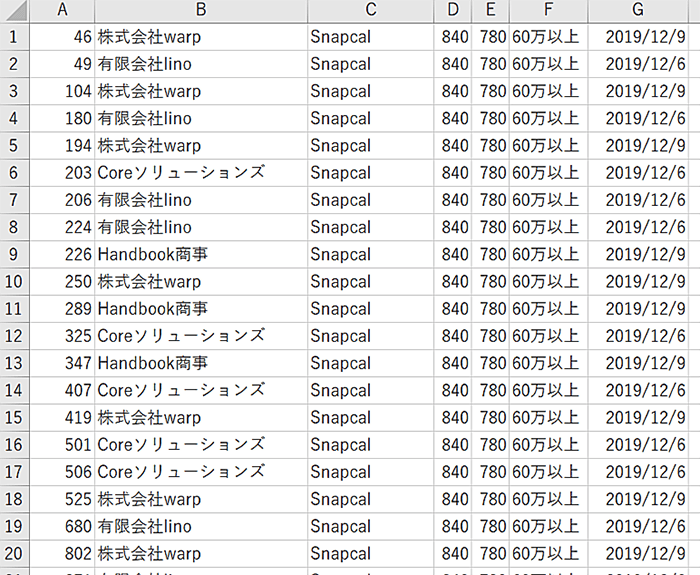
まず、条件に合致するレコードが出力され
その後、条件に条件に合致しなかったレコードが出力されます。
つまり、レコードの並び順が変わってしまう、という事ですね。
それぞれ別のファイルに出力する場合には問題ありませんが、並び順を気にする場合にはレコードをソートする処理が必要になります。
BranchStartコンポーネントと条件付きレイヤーはレコードの上から順番に処理するので並び順が変わることはありません。
同じCSVデータを利用して、
という処理を行います。
レコードの値によって出力先を振り分ける、という処理です。
条件付きレイヤーでは、条件によってレコードの受け渡し先(連携先システム)を変更する、という手順は設定できないのでこのパターンではおやすみです。
では、実行してみると、
こんな結果が得られました!
| 単位:ミリ秒 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 平均 |
| BranchStart | 12407 | 12041 | 12114 | 12025 | 12056 | 12128.6 |
|---|---|---|---|---|---|---|
| RecordFilter | 508 | 558 | 392 | 222 | 392 | 414.4 |
| 条件付きレイヤー | 実行ナシ | |||||
レコードをフィルタリングする、というのはRecordFilterコンポーネント本来の役割なので爆速ですね。
ただし、今回のテストデータは10万件(6MB程度)を単一で実行していますが、もっと大量のデータを処理する場合には、OutOfMemoryを発生させないようにループ処理と組み合わせて、一度に処理する件数を少なくしてあげる必要があります。
また、単純にフローの実行速度を比較してみるとBranchStartコンポーネントが遅いように見えますが、コンポーネント単体で比べると・・・
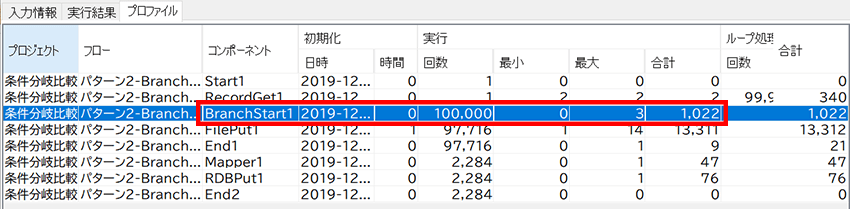
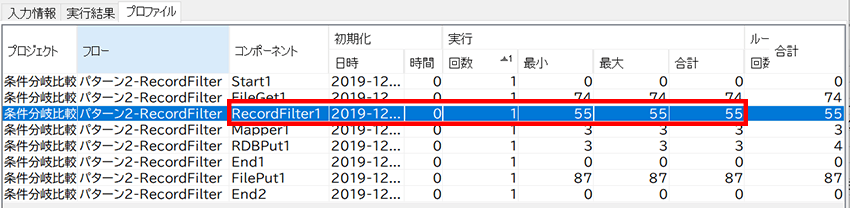
BranchStartコンポーネントは1回の実行に最大でも3ミリ秒しかかかっていないのに対し、RecordFilterコンポーネントは1回の実行に55ミリ秒かかっています。
単体でみるとBranchStartコンポーネントの方が速いんですね!
ただ、各レコードに対して条件判定をするので、同じ処理を(今回だと10万回)繰り返すのでトータルの処理時間がかかってしまいます。
今度はこんな日毎の売上データをCSVで10,000件用意してみました。
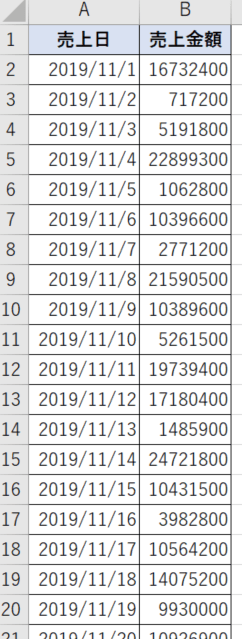
このデータにフィールド「前日比」を追加してみましょう。
と出力します。
つまり、直前のレコードの値と比較し、出力する値を分けるという事ですね。
直前のレコードの値はASTERIA Warpで扱える変数「フロー変数」に格納しておいて比較に利用します。
(変数についてはまた別の機会に!)
こういった(変数などに格納した)レコード同士の値を比較する場合には、1レコードずつ順番に変数に格納していく、という処理が必要なため、複数レコードのフィルタリングに適したRecordFilterコンポーネントは利用できません。
ということで、フローは「BranchStartコンポーネント」と「条件付きレイヤー」の2つになります。
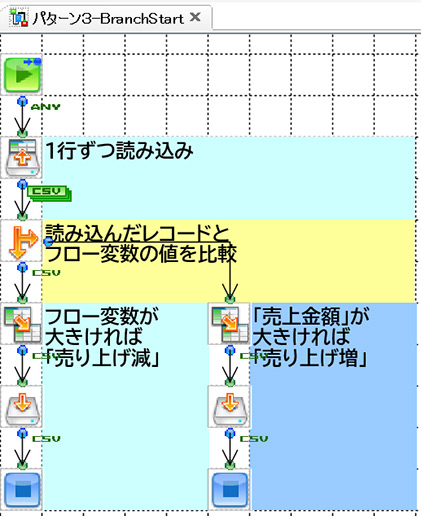
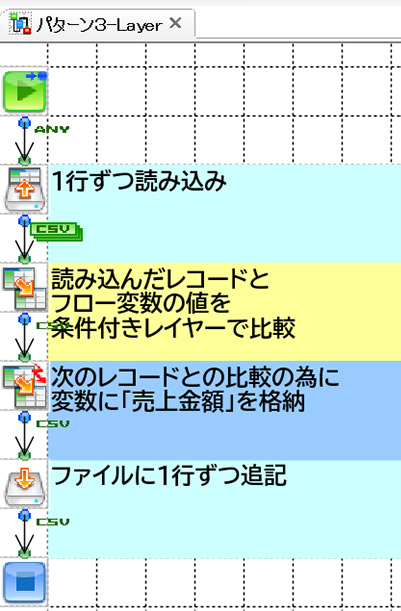
「フロー変数に格納する」という処理が増えた分、条件付きレイヤーもMapperコンポーネントが1つ追加されています。
実行速度を見てみると、ほぼ同じくらいですね。
| 単位:ミリ秒 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 平均 |
| BranchStart | 1470 | 1295 | 1309 | 1308 | 1420 | 1360.4 |
|---|---|---|---|---|---|---|
| RecordFilter | 実行ナシ | |||||
| 条件付きレイヤー | 1339 | 1295 | 1317 | 1296 | 1258 | 1301 |
むしろ、フローの全体図としては、条件付きレイヤーだとMapperコンポーネントの内部に値を判定するという処理が隠れてしまっているため、BranchStartコンポーネントの方が見通し、可読性は上がるかもしれません。
いかがでしょうか。
同じ「条件によって処理を分ける」という場合でも要件によって適したコンポーネントが違うんですね。
| パフォーマンス | 可読性 | 処理順序 | |
| BranchStart | △ | 〇 | 〇 |
|---|---|---|---|
| RecordFilter | 〇 | 〇 | △ |
| 条件付きレイヤー | ◎ | △ | 〇 |
| パフォーマンス | 可読性 | 処理順序 | |
| BranchStart | △ | 〇 | 〇 |
|---|---|---|---|
| RecordFilter | 〇 | 〇 | 〇 |
| 条件付きレイヤー | – | – | – |
| パフォーマンス | 可読性 | 処理順序 | |
| BranchStart | 〇 | 〇 | 〇 |
|---|---|---|---|
| RecordFilter | – | – | – |
| 条件付きレイヤー | 〇 | △ | 〇 |
パフォーマンスや可読性などにも大きな差が出てくるので要注意です!
条件分岐に関しては、ざっくりと、
と考えておくとよいと思います。
もちろん、実際の要件、処理するレコード数によっても変わってくるので、それぞれ確かめてみてくださいね!
今回のフローはこちらからダウンロードしてお使いいただけます↓

ASTERIA Warpのプリセールスエンジニア&体験セミナー講師。関係各所から舞い込んでくるASTERIA Warpに関するご依頼になんとか応えながら日々鍛えてもらっています!







Related Posts

ASTERIA Warp製品の技術情報やTips、また情報交換の場として「ADNフォーラム」をご用意しています。

アステリア製品デベロッパー同士をつなげ、技術情報の共有やちょっとしたの疑問解決の場とすることを目的としたコミュニティです。




![MDMコラム[入門編]第1回:マスターデータ管理(MDM)とは?メリットや進め方、導入事例をご紹介!](https://www.asteria.com/jp/wp-content/uploads/2013/01/warpblog_88671186_title01.png)