製品技術部の大木です。7/19に東京で3回目となるAUG U35勉強会を開催しました! 前回までは「若手会」という名前で運営していましたが、今回から「U35」にあらため、 年齢の目安も30歳から35歳に拡張しました。

今回は、以前からやってみたいという声が大きかった「デバッグ実践」をワークショップ形式で行いました。
出題した問題は3問!すぐに分かりそうなものからなかなか見つからない難しいものまで用意しました。 皆さん「難しい・・・!」「あともう少しでわかりそう」と悩みながら積極的に問題を説いたり質問したりしてくださり、出題者冥利につきました!
では、実際の問題をこれから簡単に解説します。正解は一つではありませんので、参考程度に確認してみてください。
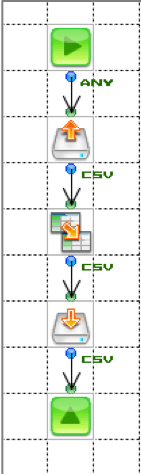
大量データを読み込み、Mapperで加工してからファイルに出力を行うフローです。 一見シンプルなフローに見えますが、このフローには次のようなバグが仕込まれていました。
これを解決するためには次の方法があります。
FileGetで20万行ほどの大量データをFileGetで一括で取得しているため、メモリを大きく消費し、エラーが発生してしまいます。
そこで、メモリの消費を抑えるためにFileGetの代わりにRecordGetを使用します。
また、最後のコンポーネントをEndResponseコンポーネントにすると大量データをレスポンスとして返すため結局OutOfMemoryが発生します。
このため、Endコンポーネントに変更する必要があります。
変更前のフローでは連番付与を「レコード番号」をマッピングすることで行っていました。
1.を解決するためにFileGetコンポーネントをRecordGetコンポーネントに変更すると、ループ処理になります。
ループ処理において「レコード番号」は繰り返し処理されるごとに1から振られてしまい、CSVファイル全体を通して連番を振ることはできません。それで連番を振るために、以下のような処理が必要です。
取得行数*(実行回数-1)+レコード番号」などの計算その他にもマッパー変数とフロー変数、Mapperをうまく組わせてつくることもできます。ぜひ、考えてみてください。
FilePutの書き込み処理を「新規」に設定すると、ループで書き込みを行うたびに最新のデータでそれまでのデータを上書きしてしまいます。
このため、書き込み処理を「追加」と設定する必要があります。
これはおまけ的なバグです。実際にといたみなさんも、気づかない方が多かったのではないでしょうか。
Mapperのなかで文字列から日付の変換処理を行っているのですが、その日付フォーマットが「yyyy/mm/dd」となっていました。
ASTERIA Warpの日付フォーマットにおいてmmは「分」を表すので、このままだと「年/分/日」という値が取得されてしまいます。
「年/月/日」を取得したいので、正しくは「yyyy/MM/dd」でした。

HTMLからCSVファイルを登録し、フロー側で受けとってデータをDBに保存、保存したデータをブラウザに表示をするフローです。このフローには次のようなバグが仕込まれていました。
これを解決するためには次の方法があります。
RecordGetの設定を見ると、インスペクタの読み込み開始行が2、プロパティの読み込み開始行も2となっています。
実は、インスペクタとプロパティの読み込み開始行は別の意味を持っています。インスペクタの読み込み開始行は取得したファイルの何行目からデータを扱うかの設定、プロパティの読み込み開始行は現在読み込んでいるレコードのうち何行目からのデータを扱うかという設定になっています。つまり、インスペクタの設定ではファイルの2行目から1行分読み込み(取得行数が1のため)ますが、プロパティの設定で2行目から読み込むことになっているため、1行しかないレコードの2行目を読み込む動作となり、値が取得できませんでした。
これを解決するには、プロパティの読み込み開始行を「1」に変更する必要があります。
ファイルからデータを取得する際には、エンコーディングに気をつけましょう。
デフォルトでは「自動判別」になっていますが、BOMなしのutf-8は自動判別できずに文字化けしてしまいます。通常、utf-8のファイルではBOMがついていることは少ないです。取得するファイルのエンコーディングがutf-8の場合は、プロパティで「utf-8」を選択することで文字化けをなくすことができます。
SQLCallでSELECTを行うときには手動でストリームの定義を行う必要があります。定義がないと何も出力されませんので、きちんと定義しましょう。
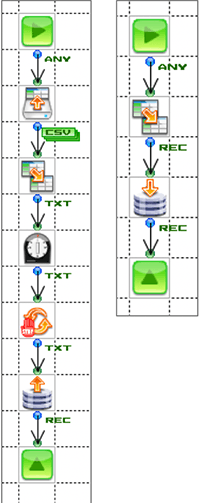
ファイルを取得してそのデータをサブフローでRDBにINSERTし、INSERTした全行をRDBから取得するフローです。
このフローを実行すると、レコードを取得できない、あるいは中途半端な行数が取得される動作となります。なぜこのような動作になるかと言うと、Timerコンポーネントで実行されたフローは別スレッドとして実行されるため、メインフローはTimerで実行するのを待つことなく、続きの処理を行います。
このため、すべてのレコードがRDBに登録される前にRDBGetを行うのでこのような実行結果となります。
これを解決するためにはいくつかの方法があります。
Timerをサブフローに置き換える
LoopEndの後ろにSleepを設置する (設定する時間によってはうまく行かないのでベストな方法ではありません。)
全レコードがRDBに登録できたかを確認する仕組みを作り、確認できたらRDBGetを実行する。
今回はどの方法を用いても正解です。ご参加いただいた方の中には、短い時間にも関わらず方法3で解いた方もいらっしゃいました!すごいですね!
実装方法はたくさんありますので、実際に皆さんで作成してみてください。
問題の解説をしてきましたが、まずどのようなバグが潜んでいるのかをデバッグするのが難しかったと思います。そこで、デバッグの助けになるようなASTERIA Warpの機能を少しご紹介します。
ワークショップのあとは皆さんでこれまでのデバッグ経験についてディスカッションを行い、技術者同士で情報を共有しました。今回の勉強会は2時間という短い時間ではありましたが、ご参加いただいた皆様のおかげで有意義な会になりました!次回のU35はどのような活動になるでしょうか。若手の皆様のご参加、お待ちしています。
また、AUGSlackのU35チャンネル「#u35勉強会」への参加もお待ちしています!
ADN Slackに参加する
※ASTERIA Warpデベロッパー向けオンラインコミュニティ(ADN Slack)は、アステリア製品オンラインコミュニティ(Asteria Park)に統合されました。ぜひご参加ください。今後ともアステリア製品を宜しくお願い致します。
▶ Asteria Parkに参加する

ASTERIA Warpの製品サポートやFAQの管理などを行っています。







Related Posts

ASTERIA Warp製品の技術情報やTips、また情報交換の場として「ADNフォーラム」をご用意しています。

アステリア製品デベロッパー同士をつなげ、技術情報の共有やちょっとしたの疑問解決の場とすることを目的としたコミュニティです。




![MDMコラム[入門編]第1回:マスターデータ管理(MDM)とは?メリットや進め方、導入事例をご紹介!](https://www.asteria.com/jp/wp-content/uploads/2013/01/warpblog_88671186_title01.png)